2. Dispatching Rule ¶
Dispatching rule is a very simple heuristic that expands only one action at each state. Therefore, starting with a single initial state, the fringe always contains a single state. Thus, at each step we trivially select the only state in the fringe. As a result, only a single goal state will be reached. Thus, The stopping criterion is also trivial: the search will stop after the first and only goal state is reached.
For example, if we are given the following state space to be searched in:
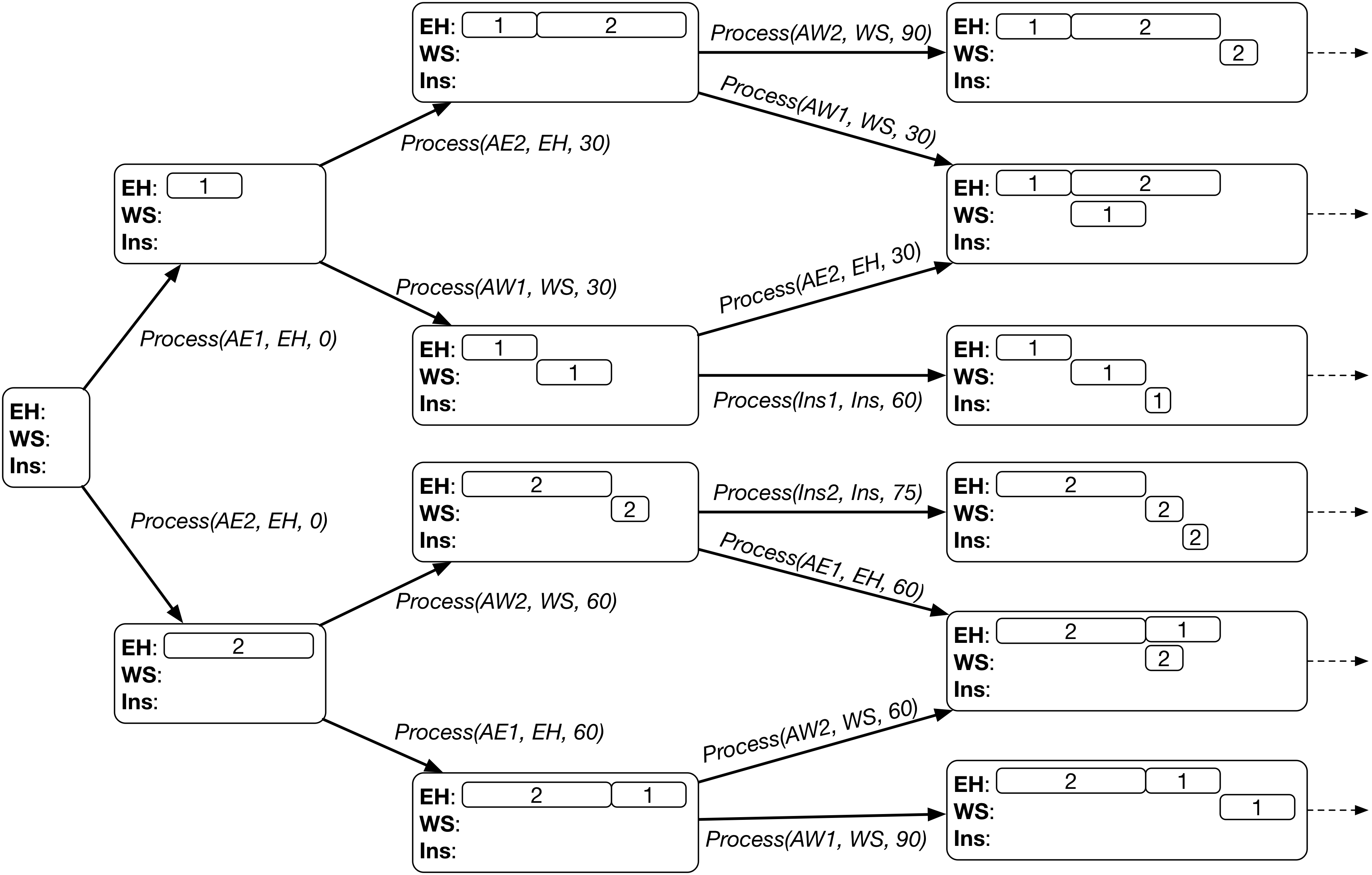
The search based on dispatching rule will select one branch (highlighted in blue boxes) at each state and finally reach a single goal state (a leaf node in the search tree).
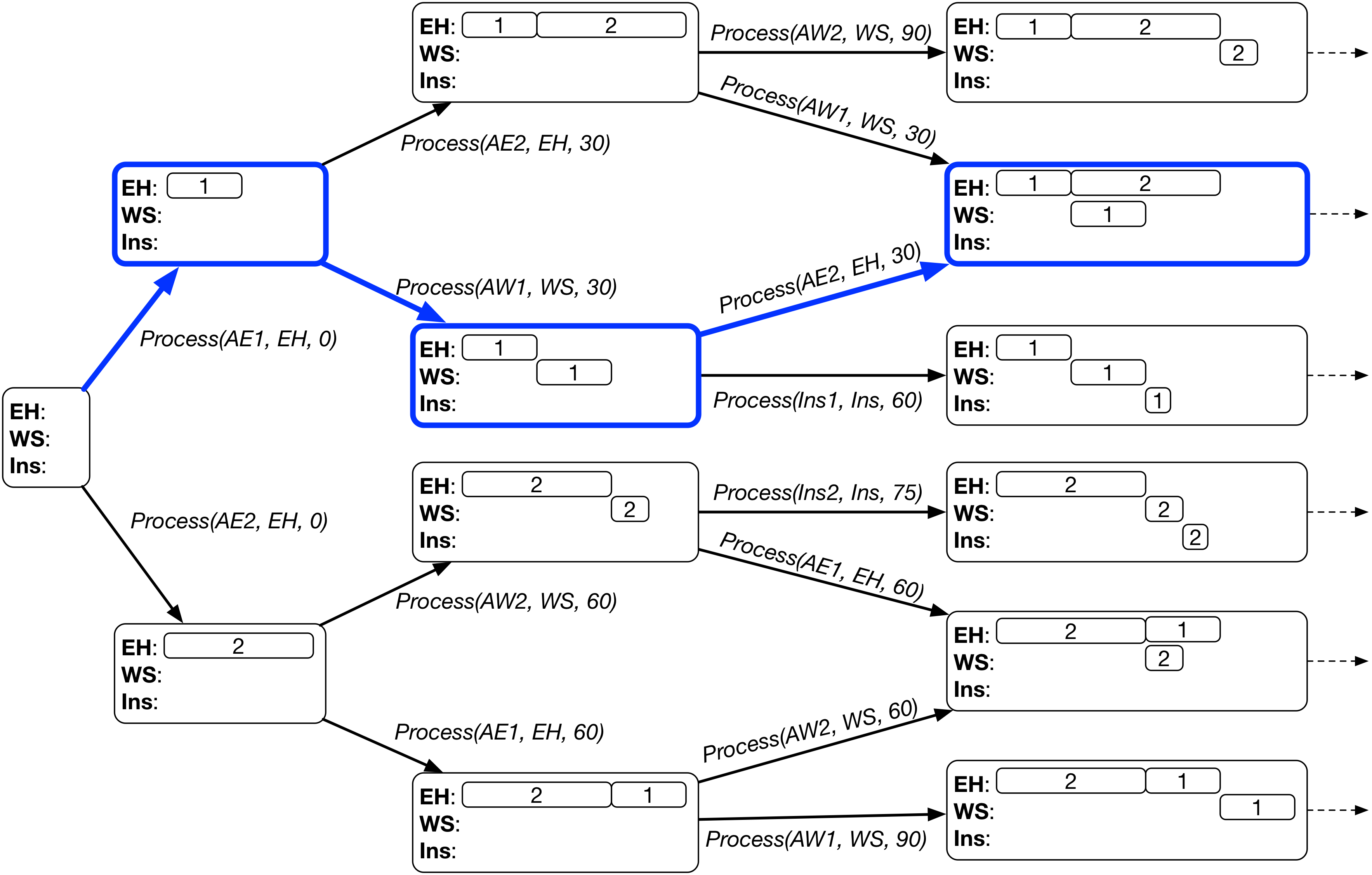
A dispatching rule selects the single action from the applicable actions based on the following two steps.
- Select the earliest applicable action (with the smallest start time).
- If there are multiple earliest applicable actions, then select an action based on the predefined priority function. Specifically, for each earliest applicable actions, a priority value in the current state is calculated by the priority function. Then, the action with the highest priority is selected.
The heuristic search based on dispatching rule can be written as follows.
Generate an initial state
# Initialise the fringe with the initial state
fringe = [initial_state]
# Search process, the fringe will become empty after the first and only goal state is reached
while fringe is not empty:
# Select the first and only state in the fringe
state = fringe[0]
if state is a goal state:
return state.schedule
Find the applicable actions at state
# Select the earliest action with the highest priority
best_action = None, earliest_time = float('inf'), best_priority = -float('inf')
for action in applicable_actions:
if action.time < earliest_time:
best_action = action, earliest_time = action.time, best_priority = priority(action, state)
elif action.time == earliest_time:
p = priority(action, state)
if p > best_priority:
best_action = action, best_priority = p
Apply best_action to state to generate next_state
Add next_state into fringe
remove state from fringe
Dispatching rule has a promising characteristic that it always expends an earliest action. Taking advantage of this characteristic, we can convert the above procedure into a much more efficient discrete event simulation procedure with priority queue.
Below are some examples of commonly used dispatching rules.
- First-Come-First-Serve (FCFS): it processes the operation that comes to the machine (becomes ready) first. The priority function can be defined as the negative ready time of the processed operation, i.e.,
priority(action, state) = - state.operation_ready_time[action.operation]. - Shortest-Processing-Time (SPT): it processes the shortest operation with the smallest processing time first. The priority function can be defined as the negative processing time, i.e.,
priority(action, state) = - action.operation.duration.
Computational Complexity¶
Assume that there are $N$ jobs and $M$ machines. Each job has $M$ operations, each to be processed by a different machine. There are $NM$ operations in total.
At each state, there can be at most $N$ applicable actions, as each job can have an operation ready. Therefore, it takes $O(N)$ time to find the best action from the $N$ applicable actions. However, only one branch is expanded.
Each action completes an operation. Thus, it takes $NM$ actions from the initial state to a goal state. In other words, the depth of the tree is $NM$.
In summary, a dispatching rule generates a chain-like search tree where each node has only one branch expanded. The entire search process visits $NM$ states, where each state takes $O(N)$ time to find the expanded branch. Therefore, the overall complexity of the dispatching rule-based heuristic search is $O(N^2M)$.
If the procedure is implemented by a discrete event simulation, for each state, we can obtain the earliest applicable actions in $O(1)$ time. In this case, we can find the best branch in $O(E)$ time, where $E$ is the number of earliest applicable action, which is usually much smaller than $N$. We can see that the discrete event simulation can greatly reduce the computational complexity to $O(NME) \ll O(N^2M)$.



