1. Job, Operation, Machine, Schedule ¶
Let's consider a car manufacturing factory. It receives jobs to build cars. For the sake of simplicity, we consider that building a car consists of the following a sequence of three main operations:
- Add Engine: This is to add the engine to the car by an Engine Hoist;
- Add Wheels: This is to add the wheels to the car by a Wheel Station;
- Inspect: After the car has been built, it has to be inspected by an Inspector.

Each operation of each job has a duration (processing time), and the required machine/resource to process it. For example, the add_engine operation requires the engine_hoist to process it, and the inspect operation is required to be processed by the inspector.
There are two constraints that a job shop schedule must satisfy:
- Resource Constraint: each machine can process at most one operation at a time.
- Precedence Constraint: each operation cannot start processing until its precedent operation in the same job has been completed (e.g.,
add_wheelscannot start untiladd_engineis completed). The first operation of a job can be started at time 0 (the job is already at the shop floor).
The goal of job shop scheduling is to find a schedule with the minimal makespan (the completion time of the last completed job), subject to the above resource and precedence constraints.
In the above car manufacturing example, let's assume that the factory has one engine_hoist, one wheel_station and one inspector, and there are two jobs described as follows:
| Job | Operation | Machine | Duration |
|---|---|---|---|
| 1 | add_engine_1 |
engine_hoist |
30 |
add_wheels_1 |
wheel_station |
30 | |
inspect_1 |
inspector |
10 | |
| 2 | add_engine_2 |
engine_hoist |
60 |
add_wheels_2 |
wheel_station |
15 | |
inspect_2 |
inspector |
10 |
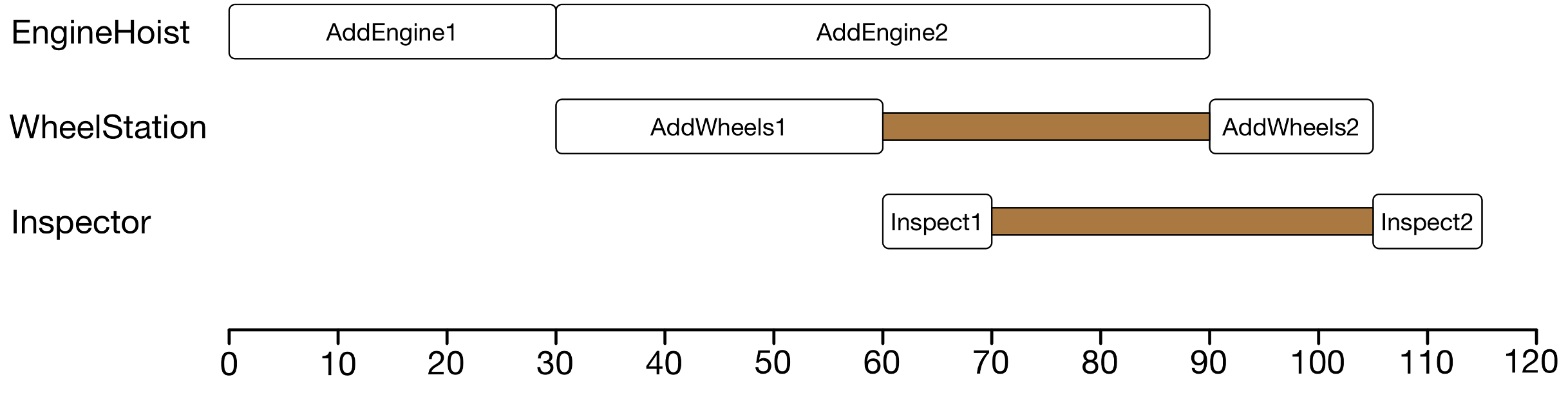
Below shows the gantt chart of two possible feasible schedules. The first schedule has a makespan of 115, while the second one has a makespan of 130.